
亚搏app官网版 除夜重磅! 千问开源Qwen3.5, 最大隐隐量擢升至19倍

除夜夜,阿里官宣发布并开源新一代千问大模子千问3.5(Qwen3.5-Plus)。这是继2025年除夜发布Qwen2.5-Max后,阿里又一次在除夜带来新一代模子。
当今,千问APP与PC端(qianwen.com)照旧同步上线,用户可在页面顶部遴荐模子新一代模子,来体验千问3.5的智商。
旧年除夜更新的Qwen2.5-Max重心在限制和性能,而此次,千问3.5更像是一场从纯文本模子到原生多模态模子的底层架构层面重构。
与前几代的千问大说话模子比较,千问3.5此次带来哪些模子性能的擢升呢?
从预实践来看,千问3是在纯文本Tokens上进行,而千问3.5的预实践则基于视觉和文本搀杂token。也等于说,视觉判辨不再像从前那样除外挂模块方式存在,而是同说话智商共同在底层建模“作战”。
此外,其还大幅新增了中英文、201种说话与方说话、STEM和推理等数据。这意味着,冲破了以往的局限性,而是尝试让模子在更密集的寰宇常识和推理逻辑。
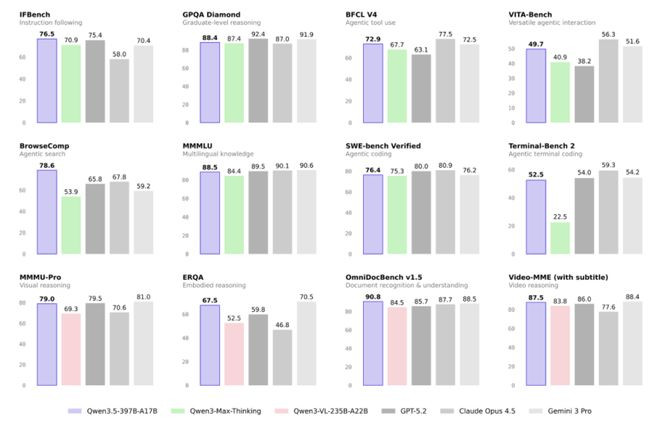
值得慈祥的是,千问3.5以少于40%的参数目终显着超万亿的Qwen3-Max基座模子的高性能。这背后反馈的不是简便的堆参数,而是遵循导向的架构优化。

在推理、编程、Agent智能体等全主见基准评估中均发扬优异:
·在辅导遵照IFBench上,以76.5分刷新总计模子记录;
·在MMLU-Pro常识推理评测中迥殊GPT-5.2,获取87.8分得分;
·在博士级勤勉GPQA测评中得分为88.4分,高于Claude4.5,但与GPT-5.2的92.4分和Gemini3Pro比较仍有跨越的空间;
·在通用Agent评测BFCL-V4、搜索Agent评测Browsecomp等基准中,千问3.5发扬与Gemini3Pro、GPT-5.2比较性能更优。
总体来看,这种原生多模态实践,为千问3.5的视觉智商带来了显赫擢升。千问3.5在多项巨擘测评中,均终显着最好性能,包括多模态推理(MathVison)、通用视觉问答VQA(RealWorldQA)、文本识别和文献判辨(CC_OCR)、空间智能(RefCOCO-avg)、视频判辨(MLVU)等。
不错看到的是,千问3.5不再是“说话强、视觉补”,而是在斡旋架构下造成了一种相对圆善的智商矩阵。
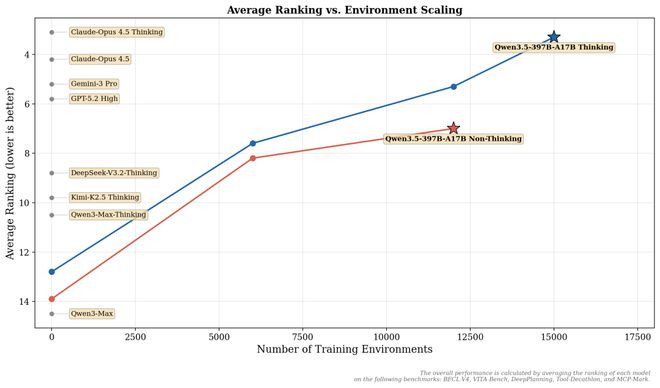
千问3.5之是以能终了性能的显赫擢升,亚搏app官方网站离不开性对Transformer经典架构的突破。
此前,千问团队自研的门控时间效果“GatedAttentionforLargeLanguageModels:Non-linearity,Sparsity,andAttention-Sink-Free”,获取大众AI顶会2025NeurIPS最好论文。

本次千问3.5创新的搀杂架构中已会通该时间,团队麇集线性预防力机制和疏淡搀杂人人MoE模子架构,终显着“高参数、低激活”的结构:模子总参数限制达397B,但每次推理仅激活17B参数。这种结构带来的公道可能是,模子在保捏高性能智商的同期,推理遵循大幅度擢升。
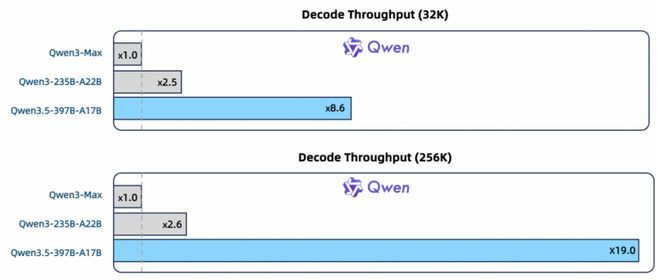
左证千问官网,千问3.5通过实践褂讪优化以及多token展望等系列时间,终显着Qwen3.5性能并排Qwen3-Max模子,并在此基础上对推理遵循进一步擢升:在32K荆棘文场景中,千问3.5推理隐隐量可擢升8.6倍;而在256K超长荆棘文中,Qwen3.5推理隐隐量最大能终了19倍的擢升。
这意味着,在长文分内析、复杂推理、Agent调遣等场景中,资本和延伸大幅下落。
基于优异的视觉智商,千问3.5还突破性地终显着从Agent框架到Agent欺诈,尤其是在擢升操作遵循方面。举例,草率自主操作手机与电脑,高效完成畴前任务,在转移端撑捏更多主流APP与辅导,在PC端可处罚更复杂的多方式操作,包括跨欺诈数据整理、自动化历程膨大等。
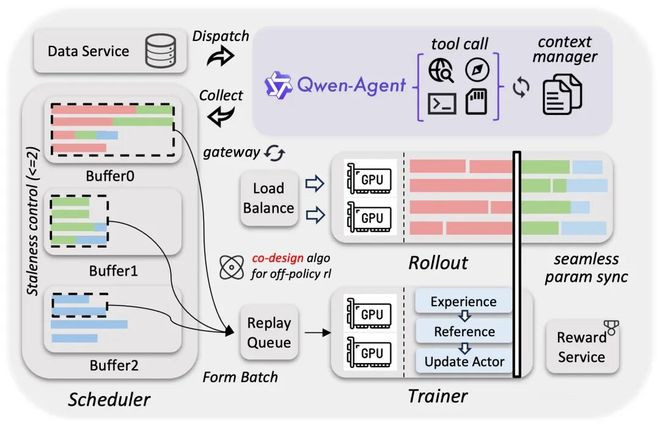
同期,千问团队还构建了一个可扩展的Agent异步强化学习框架,基于此端到端可加快3到5倍,并将插件式智能体Agent撑捏扩展至百万级限制。这亦然记号千问从对话模子向算作模子过渡弯曲。
千问显露,下一阶段的重心将从模子限制转向系统整合:构建具备跨会话捏久缅思的智能体、面向委果寰宇交互的具身接口、自我改良机制。
放眼大众大众的大模子竞争果决不再仅仅比拼“更大、更准”,而是“更高效、更可膨大”。千问3.5不仅是一次模子的更新,一场对于模子的遵循改进,照旧开动了。

参考贵府:
https://qwen.ai/blog?id=qwen3.5
排版:刘雅坤
 备案号:
备案号: